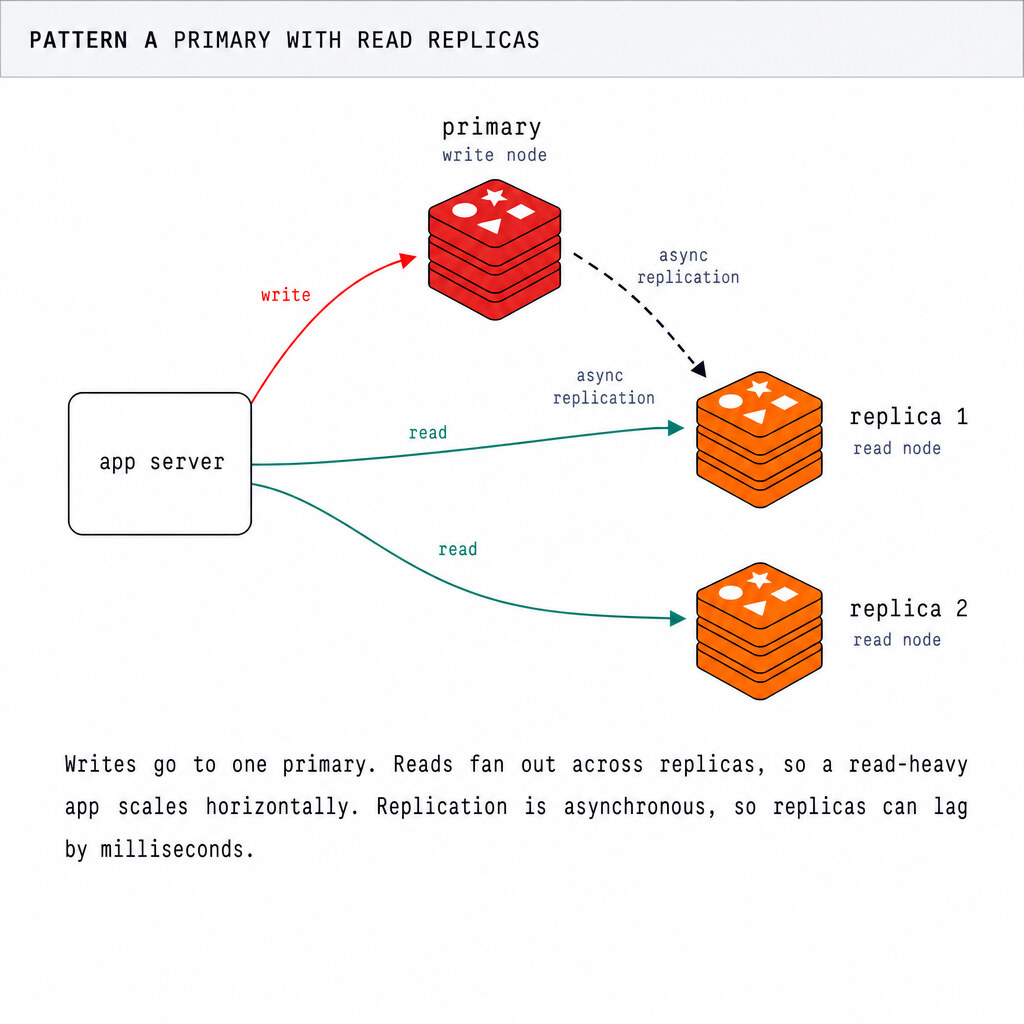
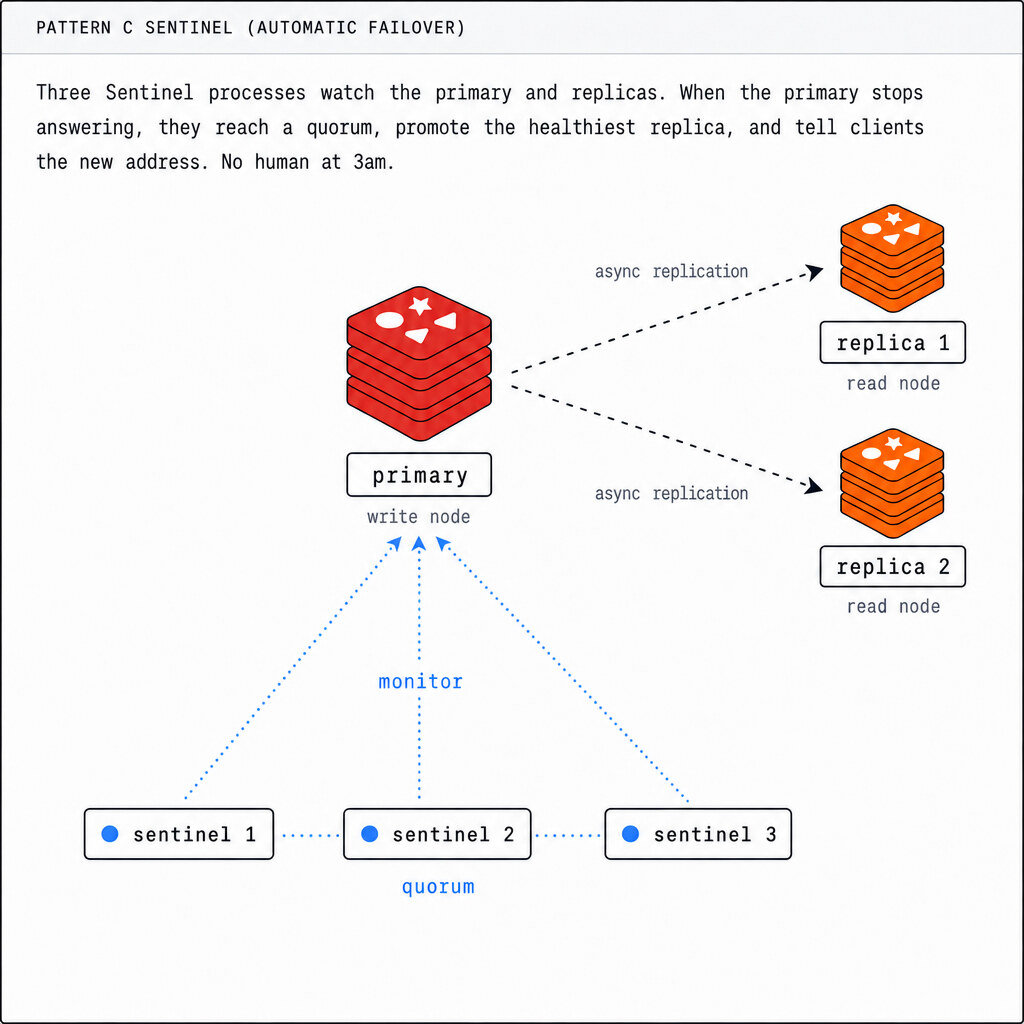
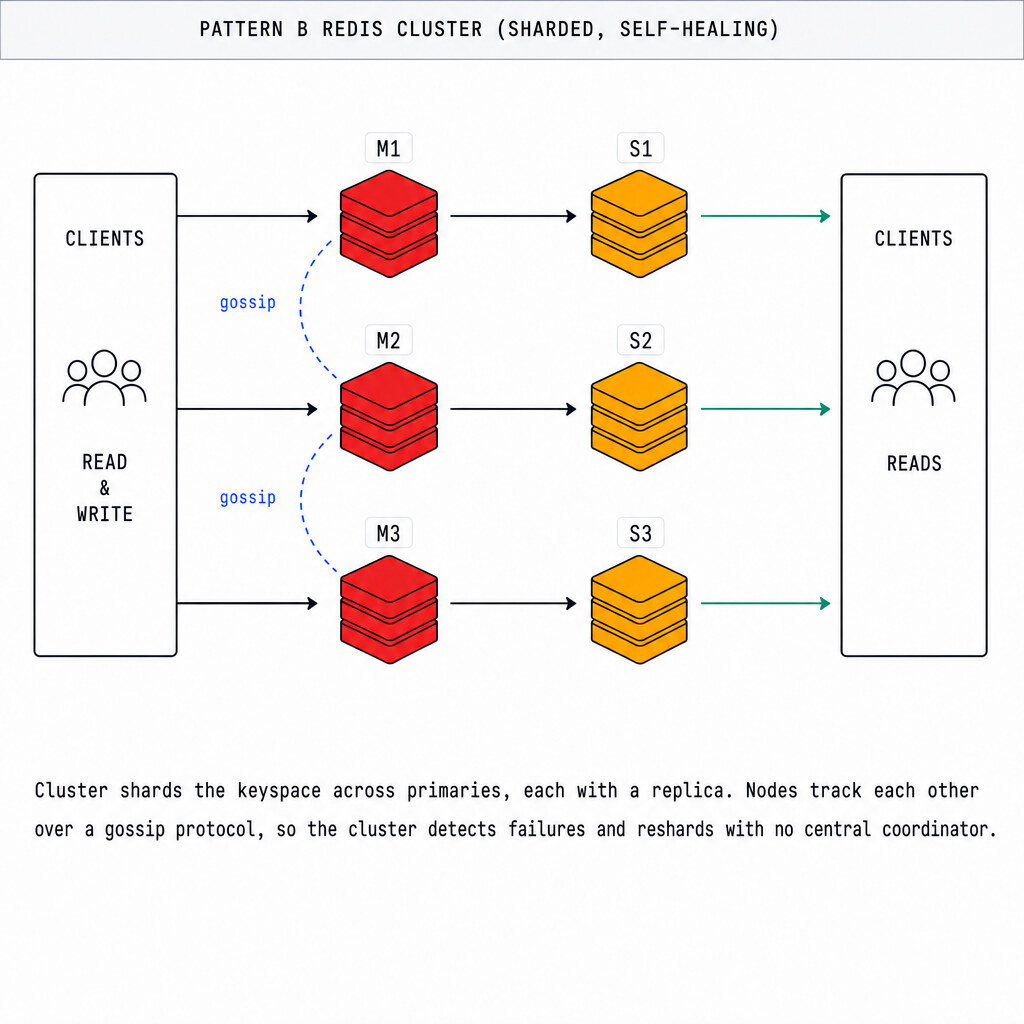
- Is Redis a database or a cache?
- Both, and that is the point of confusion. Redis is an in-memory data store. Most teams first meet it as a cache in front of PostgreSQL, but it is also a capable primary store for the right workloads, a message broker, a rate limiter, and now a vector store for AI. We treat your relational database as the source of truth and let Redis be the fast layer in front of it unless a workload genuinely calls for more.
- Will I lose data if Redis restarts?
- Only if you configure it to. Redis keeps data in memory for speed, but it persists to disk with RDB snapshots, an append-only file (AOF), or both. Production runs the hybrid mode: fast recovery from snapshots plus minimal loss from the AOF. We tune the durability knobs to the data, sessions and caches can be looser, anything you cannot recompute is not.
- Redis or just add more PostgreSQL?
- Postgres is remarkably capable and we reach for it first. Redis earns its place when you need sub-millisecond reads on hot data, atomic counters at high write rates, rate limiting, sessions shared across servers, lightweight queues, or pub/sub fan-out. The test is simple: if the database is doing repeated, expensive work to answer the same question, a cache in front of it is usually the cheaper win.
- Do I still need a separate vector database for RAG?
- Often no. Since Redis folded vector search, JSON, and search into the core, you can store embeddings next to their metadata and run similarity search in one system. For small to mid-scale retrieval that removes a whole moving part. A dedicated vector store earns its place at large scale or with specialized indexing needs.
- How do you keep Redis from becoming a liability?
- Discipline. Namespaced keys, a TTL on everything, an eviction policy chosen on purpose, connection pooling, circuit breakers so the app degrades gracefully when Redis is unavailable, and no KEYS or FLUSHALL in production. We also make it observable: hit rate, memory fragmentation, and latency tracked from day one.